

我们来看spark非常重要的一个概念——rdd。
在上一讲当中我们在本地安装好了spark,虽然我们只有local一个集群,但是仍然不妨碍我们进行实验。spark最大的特点就是无论集群的资源如何,进行计算的代码都是一样的,spark会自动为我们做分布式调度工作。
RDD概念
介绍spark离不开RDD,RDD是其中很重要的一个部分。但是很多初学者往往都不清楚RDD究竟是什么,我自己也是一样,我在系统学习spark之前代码写了一堆,但是对于RDD等概念仍然云里雾里。
RDD的英文全名是Resilient Distributed Dataset,我把英文写出来就清楚了很多。即使第一个单词不认识,至少也可以知道它是一个分布式的数据集。第一个单词是弹性的意思,所以直译就是弹性分布式数据集。虽然我们还是不够清楚,但是已经比只知道RDD这个概念清楚多了,
RDD是一个不可变的分布式对象集合,每个RDD都被分为多个分区,这些分区运行在集群的不同节点上。
很多资料里只有这么一句粗浅的解释,看起来说了很多,但是我们都get不到。细想有很多疑问,最后我在大神的博客里找到了详细的解释,这位大神翻了spark的源码,找到了其中RDD的定义,一个RDD当中包含以下内容:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
我们一条一条来看:
- 它是一组分区,分区是spark中数据集的最小单位。也就是说spark当中数据是以分区为单位存储的,不同的分区被存储在不同的节点上。这也是分布式计算的基础。
- 一个应用在各个分区上的计算任务。在spark当中数据和执行的操作是分开的,并且spark基于懒计算的机制,也就是在真正触发计算的行动操作出现之前,spark会存储起来对哪些数据执行哪些计算。数据和计算之间的映射关系就存储在RDD中。
- RDD之间的依赖关系,RDD之间存在转化关系,一个RDD可以通过转化操作转化成其他RDD,这些转化操作都会被记录下来。当部分数据丢失的时候,spark可以通过记录的依赖关系重新计算丢失部分的数据,而不是重新计算所有数据。
- 一个分区的方法,也就是计算分区的函数。spark当中支持基于hash的hash分区方法和基于范围的range分区方法。
- 一个列表,存储的是存储每个分区的优先存储的位置。
通过以上五点,我们可以看出spark一个重要的理念。即移动数据不如移动计算,也就是说在spark运行调度的时候,会倾向于将计算分发到节点,而不是将节点的数据搜集起来计算。RDD正是基于这一理念而生的,它做的也正是这样的事情。
创建RDD
spark中提供了两种方式来创建RDD,一种是读取外部的数据集,另一种是将一个已经存储在内存当中的集合进行并行化。
我们一个一个来看,最简单的方式当然是并行化,因为这不需要外部的数据集,可以很轻易地做到。
在此之前,我们先来看一下SparkContext的概念,SparkContext是整个spark的入口,相当于程序的main函数。在我们启动spark的时候,spark已经为我们创建好了一个SparkContext的实例,命名为sc,我们可以直接访问到。
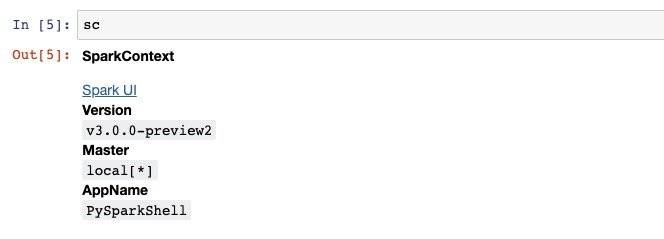
我们要创建RDD也需要基于sc进行,比如下面我要创建一个有字符串构成的RDD:
texts = sc.parallelize(['now test', 'spark rdd'])返回的texts就是一个RDD:

除了parallelize之外呢,我们还可以从外部数据生成RDD,比如我想从一个文件读入,可以使用sc当中的textFile方法获取:
text = sc.textFile('/path/path/data.txt')一般来说,除了本地调试我们很少会用parallelize进行创建RDD,因为这需要我们先把数据读取在内存。由于内存的限制,使得我们很难将spark的能力发挥出来。
转化操作和行动操作
刚才我们在介绍RDD的时候其实提到过,RDD支持两种操作,一种叫做转化操作(transformation)一种叫做行动操作(action)。
顾名思义,执行转化操作的时候,spark会将一个RDD转化成另一个RDD。RDD中会将我们这次转化的内容记录下来,但是不会进行运算。所以我们得到的仍然是一个RDD而不是执行的结果。
比如我们创建了texts的RDD之后,我们想要对其中的内容进行过滤,只保留长度超过8的,我们可以用filter进行转化:
textAfterFilter = texts.filter(lambda x: len(x) > 8)我们调用之后得到的也是一个RDD,就像我们刚才说的一样,由于filter是一个转化操作,所以spark只会记录下它的内容,并不会真正执行。
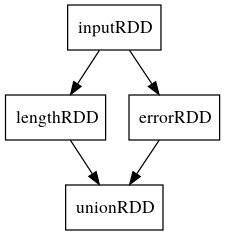
转化操作可以操作任意数量的RDD,比如如果我执行如下操作,会一共得到4个RDD:
inputRDD = sc.textFile('path/path/log.txt')
lengthRDD = inputRDD.filter(lambda x: len(x) > 10)
errorRDD = inputRDD.filter(lambda x: 'error' in x)
unionRDD = errorRDD.union(lengthRDD)最后的union会将两个RDD的结果组合在一起,如果我们执行完上述代码之后,spark会记录下这些RDD的依赖信息,我们把这个依赖信息画出来,就成了一张依赖图:
无论我们执行多少次转化操作,spark都不会真正执行其中的操作,只有当我们执行行动操作时,记录下来的转化操作才会真正投入运算。像是first(),take(),count()等都是行动操作,这时候spark就会给我们返回计算结果了。

其中first的用处是返回第一个结果,take需要传入一个参数,指定返回的结果条数,count则是计算结果的数量。和我们逾期的一样,当我们执行了这些操作之后,spark为我们返回了结果。
本文着重讲的是RDD的概念,我们下篇文章还会着重对转化操作和行动操作进行深入解读。感兴趣的同学不妨期待一下吧~

